What's the problem
The biggest pain I had for my first week at my First Real Job was writing and maintaining extremely repetive code, mainly in tests. The problem wasn't the wrong attitude. Resolver programmers follow all best practices, and besides they are really, really smart guys. The problem seems to appear, when the repetition is very small and local.
Let's say you've got a function taking 5 args. You want to invoke it 10 times with 2 arguments changing and 3 staying the same. The cost of encapsulating it into another function is small, but it's still bigger than using copy-pasting it. What's more: you often get _more_ readable code than extracting common parts. The conclusion is: generalization is good and helps you unless you're operating on a very small scale.
However, following the example: what if you spot an error in your not-changing parameters? You have two choices: either correcting the same 5-character mistake in every line, or using a regexp.
Regular expressions are not user-friendly
OK, so, as someone wise once said: You've got a problem. You decide to use regexp to solve it. Now you've got two problems. Regular expressions are relatively simple (after you learn it buhaha:>) yet powerful tool for automated text processing. You take your mistake repeated 10 times in your code, apply a regexp to it, and voila: everything's broken. You forgot some fancy-dancy character which spoils the whole thing. That's not a problem: you fix your regexp, and everything's fine. Yeah, but by this time you could have fixed your code two times manually.
I know, it's a matter of seconds if not less, but: 1. Seconds tend to acculumate fast; 2. It's a pain in the ass isn't it?
Ok, so how can we make using regexps faster? Two reasons why people don't use them in _really_ small changes are: 1. The time to find out and enter a regexp is often taking longer than adding changes manually; 2. Poeple tend to make mistakes, and debugging a thing that is to change 10 lines of code is WRONG! A solution which seem to get rid of both these problems is automated regexp generation. Of course, you can use it only in a subset of described problems, but I think it could do its job.
An example: managing the border in some GUI application. For some reason I had to set each Border in a seperate line:
a.LeftBorder = True
a.TopBorder = True
a.RightBorder = True
a.BottomBorder = True
I ran it and... KABOOM, an exception. Yeah, right it's not LeftBorder but BorderLeft etc. Not good. I fixed the code using mouse (okay, I didn't: I downloaded vim, installed it, retried the regexp 3 times, and got it replaced. Really). Anyway, I had pretty much time to imagine the tool I'd love to use. Something, that would get the lines, find the similarity and suggest a replacement, which I could then change _once_, without any entering any regexp. And all of it under ONE keystroke (ok, maybe two). Actually, I started looking for a way to find such similarities, and found Jacob Kaplan Moss' TemplateMaker, which could do the job.
I happened to reproduce the algorithm or, at least, something similar to it that would suit my requirements. I turned out to be pretty straitforward 15-liner. It should work best as a plug-in to your favourite text editor, but, since I wanted it to be portable, I wrote a seperate GUI (in wxPython - portability) for it. Some things which may surprise you are automatic clipboard capture on load, and clipboard filling on every replacement editing (couldn't find wxPythons onClose event), so you'll get an exception on copy-pasting replacement field. Anyway: Take a look:
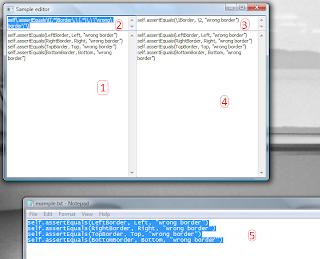
Say you've got some text you want to refactor locally, like in the notepad (5) instance on the screenshot. You copy it, run the tool, which:
- captures the clipboard content and puts it into input text box (1)
- runs my templateMaker clone and finds a regexp that suits best to input lines (and puts it in box (2))
- gets the same expression in the form of replacement (with backreferences)
- runs the re.sub function, that generates output text (put then in (4))
The only thing you have to do is to change replacement (although there's nothing that prevents you from editing other fields, which is quite useful when the regexp was not guessed properly). As I mentioned before: the clipboard gets filled on every change of textbox (3), which is definitely a bug of mine (which should be corrected shortly :>). Have fun
